Det tekniske
I TALT-projektet har vi beskæftiget os med innovative løsninger inden for den kommunale sygepleje. Formålet var at undersøge, hvorvidt man kan bygge værdiskabende løsninger med AI, som enten automatiserer eller effektiviserer arbejdsprocesser for personalet.
Projektets primære metode, for at vurdere kvaliteten af vores løsninger, var indsamling af feedback fra fagligt personale i forbindelse med afprøvninger i 11 kommuner (de tre projektkommuner og øvrige 8 afprøvningskommuner). For alle use cases er afprøvningerne derfor understøttet af en afprøvningsklient, som er udviklet med henblik på bedst muligt at fremvise systemoutputs og indsamle feedback – og ikke med et driftsscenarie for øje.
Her på siden får du et overblik over den tekniske opsætning af løsningerne - både af Data Science-komponenter og afprøvningsklienter - og et udsnit af de opnåede resultater. Du får desuden en række indsigter og anbefalinger til, hvordan man arbejder videre med og idriftsætter løsninger med Data Science komponenter i en sygeplejefaglig kontekst.
Hvis nedenstående information har din interesse, kan du læse meget mere i dokumentet ‘Vej til drift’.
De tre use cases
Fold alle ud
UC1: Sygeplejefaglig udredning
Use casen omhandler støtte til oprettelse af sygeplejetilstandsnotater på baggrund af en sygeplejefaglig udredningssamtale (SFU-samtalen) mellem borger og sygeplejerske. Støtten ydes gennem udkast til notater baseret på samtalens indhold.
Tekniske løsning
Teknisk understøttes løsningen ved, at SFU-samtalen optages og efterbehandles af sygeplejersker i afprøvningsklienten. Udkast til journalnotater genereres ved, at samtalen transskriberes via en talegenkendelsesmodel (TGK). Den resulterende tekst klassificeres på de 12 sygeplejefaglige problemområder, hvorefter relevante sygeplejetilstandsnotater genereres via en stor sprogmodel.
En række komponenter er udviklet til at opnå ovenstående løsning og for at sikre, at projektets behov for udvikling, afprøvning og dataindsamling kan understøttes af den samlede tekniske løsning.
Se figur UC1 nederst på denne side for et samlet overblik over komponentarkitekturen for løsningen.
Du kan læse mere om modeller trænet og data indsamlet i forbindelse med udvikling og afprøvning af løsningen i dokumentet ‘Data og modeller’.
Resultater
I forbindelse med afprøvning af løsningen har sygeplejersker fra projektets 11 afprøvningskommuner indtalt og efterbehandlet syntetiske SFU-samtaler i afprøvningsklienten. Her behandles den konkrete samtale ved, at løsningens udkast til journalnotater (opsummeringer) sammenholdes med den komplette liste af sygeplejetilstande, der på baggrund af samtalen bør oprettes notater til. Vi refererer til denne liste som de relevante sygeplejetilstande. Dernæst tager sygeplejersken stilling til, hvorvidt den enkelte opsummering kræver rettelser for at være fyldestgørende. Afslutningsvis markeres irrelevante sygeplejetilstande.
Evaluering på tværs af alle relevante sygeplejetilstande fordelt på afprøvningerne viser, at løsningen generede et udkast til notat, der blev godkendt uden rettelser i ca. 30 % af tilfældene, og et notat, der blev godkendt med rettelser i ca. 50 % af tilfældene. Det giver en samlet præcision på ca. 80 %. De resterende ca. 20 % af tiden generede løsningen altså ikke et notat til en forventet sygeplejetilstand. Løsningen leverer fejlagtigt udkast til notater til ca. 10 % af de ikke relevante sygeplejetilstande.
En analyse af årsager til fejl i udkastene indikerer, at alle 3 komponenter ofte begår fejl med en lille overvægt til opsummeringskomponenten.
Videreudvikling
Analyse af forskellige videreudviklingsmetoder indikerer at evalueringsdata indsamlet i forbindelse med afprøvninger har tydelige begrænsninger, da der forekommer en betydelig grad af bias, hvor løsningens udkast har påvirket efterbehandlingen.
Derfor er fokus for videreudvikling af UC1 etablering af et evalueringssæt – gerne med udgangspunkt i ægte data. Dette for at danne en mere fyldestgørende forståelse for løsningens egentlige potentiale for at skabe værdi og for bedre at belyse potentielle forbedringsmuligheder.
UC2: Journalopsummering
Use casen omhandler opsummering af borgerjournal til støtte ved borgerbesøg udført af hhv. sygeplejersker (SPL) og social- og sundhedsassistenter og -hjælpere (SSA/SSH). Dette med henblik på at nedbringe forberedelsestiden og øge kvaliteten af forberedelsen for personalet inden et besøg hos en borger. Der er i projektet blevet kigget på at lave generelle opsummeringer af borgerens journal, der henvender sig til SSA/SSH og nye medarbejdere, vikarer samt meget generelle besøgskontekster inden for sygeplejen.
Teknisk løsning
Løsningen er bygget op omkring en præsentation af borgerens journaldata fra den elektroniske omsorgsjournal (EOJ), der bliver struktureret og givet til en stor sprogmodel, der genererer opsummeringen af journalen. Prompten blev initialt tunet med en mindre mængde af journalerne op imod fagligt genererede opsummeringer af journaler og efterfølgende ud fra feedbacken fra afprøvningerne.
Trænings-flowet er illustreret på en figur længere nede på siden her og indeholder følgende skridt:
- Det faglige personale indskriver journalfelter for hver borger i et digitalt skema.
- Data processeres ved at udtrække data fra journalpræsentationen og strukturere det således, at data kan indhentes og indsættes korrekt i prompten af sprogmodellen.
- Den generative sprogmodel genererer en journalopsummering baseret på journaldataen. Prompten tunes initialt med henblik på at generere opsummeringer, der ligner de manuelt genererede opsummeringer.
- Opsummering og tilhørende journaldata indskrives i databasen
- Opsummering og tilhørende journaldata indlæses af afprøvningsklienten.
- Fagligt personale tilgår afprøvningsklienten og giver opsummeringerne en rating og feedback-kommentar.
- Rating og feedback journaliseres i databasen.
Resultater
Evalueringen af UC2-løsningen er udført gennem indhentning af faglige vurderinger ifm. afprøvning. Der blev afholdt en ekstern afprøvning i projektets 11 afprøvningskommuner for de sygplejefaglige opsummeringer. De gav en gennemsnitlig rating på 4,5 på en skala fra 1-6.
Videreudvikling
Videreudviklingen af denne løsning skal bygge ovenpå det potentiale, der er blevet vist til afprøvningerne i projektet. Det anbefales at fokusere på at vise, at systemet også kan yde en tilfredsstillende og værdiskabende generel opsummering med ægte journaldata og med al relevant journaldata udtrukket direkte fra EOJ’en.
Første skridt er derfor at undersøge, hvilken data der er relevant for de generelle journalopsummeringer, og hvorvidt det er muligt at lave en udtrækning og repræsentation af data. Når dette er på plads, kan det undersøges med samme tekniske flow som illustreret i figuren UC2 (kan ses længere nede på siden) - og med tilsvarende prompts - om løsningen kan generere værdifulde opsummeringer.
Hvis de generelle opsummeringer viser gode resultater, vil det være muligt at bygge ovenpå med besøgsspecifikke opsummeringer. Disse er rettet mod sygeplejerskerne, der typisk foretager besøg med en specifik besøgskontekst.
UC3: Indtaling af besøgsbeskrivelser
Use casen omhandler støtte til oprettelse og opdatering af besøgsbeskrivelser til hjælp med hjemmebesøg udført af SSA/SSH. Besøgsbeskrivelserne oprettes på baggrund af en indtaling. Støtten skulle gerne gøre det muligt at indtale i hverdagssprog og uden særligt hensyn til den endelige struktur.
Tekniske løsning
Teknisk understøttes den støtte ved, at sundheds- og omsorgsassistenter og -hjælpere (SSA/SSH) indtaler en besøgsbeskrivelse og efterbehandler udkastet i afprøvningsklienten. Udkastet genereres ved, at indtaling transskriberes via en talegenkendelsesmodel (TGK), dernæst genereres et udkast til en besøgsbeskrivelse på baggrund af transskriberingen med en stor sprogmodel. En eksisterende besøgsbeskrivelse kan ligeledes opdateres ved en tilsvarende indtaling.
En række komponenter er udviklet til at opnå ovenstående løsning og for at sikre. at projektets behov for udvikling, afprøvning og dataindsamling kan understøttes af den samlede tekniske løsning.
Se figuren UC3 nederst på siden for et samlet overblik over komponentarkitekturen for løsningen.
Resultater
I forbindelse med afprøvning af løsningen har sygeplejersker fra projektets 11 afprøvningskommuner oprettet, rettet og opdateret syntetiske besøgsbeskrivelser i afprøvningsklienten. Hver oprettelse bliver tildelt en rating fra 1-4 med en samlet gennemsnitlig score på 3,04. Opdateringer er ligeledes blevet tildelt en rating fra 1-4 og har en samlet score på 3,27.
Videreudvikling
En klassificering af årsagen til de rettelser, det faglige personale indfører i løsningens udkast, giver følgende hyppigste fejlkilder: Hallucinationer fra sprogmodellen, transskriberingsfejl og terminologifejl.
Videreudvikling bør derfor i udgangspunktet fokusere på at udbedre disse fejl. En analyse udført i projektet indikerer et potentiale for, at sprogmodellen kan efterbehandle udkastet med fokus på at begrænse hallucinationer.
I forlængelse af forbedrede udkast til besøgsbeskrivelser anbefaler vi, at muligheden for at opnå tilstrækkelig kvalitet med mindre sprogmodeller afdækkes, da dette giver øget fleksibilitet i forhold til udvikling og driftsscenarier.
For at minimere sandsynligheden for, at løsningen forårsager fejl i plejen, bør løsningen implementeres med kvalitetstjek af lyd, transskription og udkast.
Hvad er næste skridt?
For at kunne sætte projektets løsninger i drift, er der en lang række ting, som man først skal håndtere:
- Integration til EOJ-system: Værdiskabelse skal være tilgængelig tæt på eksisterende processer.
- Afklaring af ressourcebehov: AI-løsninger kan variere meget i ressourcebehov.
- Etablering af skalerbarhed: Løsninger med kort svartid kan kræve store mængder specialiseret hardware.
- Etablering af miljøer: Både modeller og software har behov for separate udviklings-, test, og produktionsmiljøer.
- Opsætning af logning og metrikker: Logning og metrikker er centrale værktøjer for at sikre stabil drift.
- Håndtering af kommunespecifikke krav og variationer: Processer og sygeplejefaglig praksis er ikke ens på tværs af landet.
- Organisatorisk forankring: Løsningerne skal forankres i organisationen for at sikre den forventede værdiskabelse.
Alle ovenstående punkter skal håndteres med hensyn til den konkrete tekniske løsning, hvorfor den påkrævede indsats kan variere meget fra løsning til løsning.
Kodebase, modeller og datasæt
Du kan læse om kodebasen i dokumentet ‘Kode og udviklingsmiljø’ og om projektets datasæt og modeller i dokumentet ‘Data og modeller’.
Datasæt, modeller og kodebase er desuden offentliggjort. Du finder alle relevante rapporter og links til kodebase, modeller og datasæt i boksen herunder.
Kodebase og modeller
UC1: Sygeplejefaglig udredning
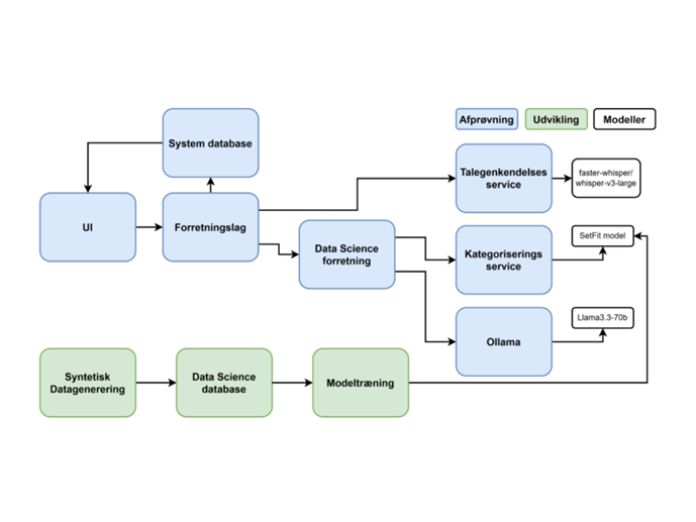
Følgende er en kort beskrivelse af de centrale komponenter:
- UI: Afprøvningsklientens brugergrænseflade, udstilling af løsningen til brugere i forbindelse med afprøvning samt interne projektfolk i forbindelse med test og udvikling.
- Forretningslag: Afprøvningsklientens forretningslag, til understøttelse af brugergrænsefladen og sammenkobling mellem system og database.
- Data Science forretning: Koblingspunkt mellem afprøvningsklienten og Data Science komponenterne samt forretningslogik.
- Talegenkendelsesservice: API til udstilling af Whisper-model.
- Kategoriseringsservice: API til udstilling af kategoriseringsmodel
- Ollama: API til udstilling af sprogmodeller
- Syntetisk datagenerering: Modul til generering af syntetiske SFU-samtaler brugt til udvikling af Data Science komponenterne. Læs mere om dette modul i supplerende dokument ‘Syntetisk datagenerering’.
UC2: Journalopsummering
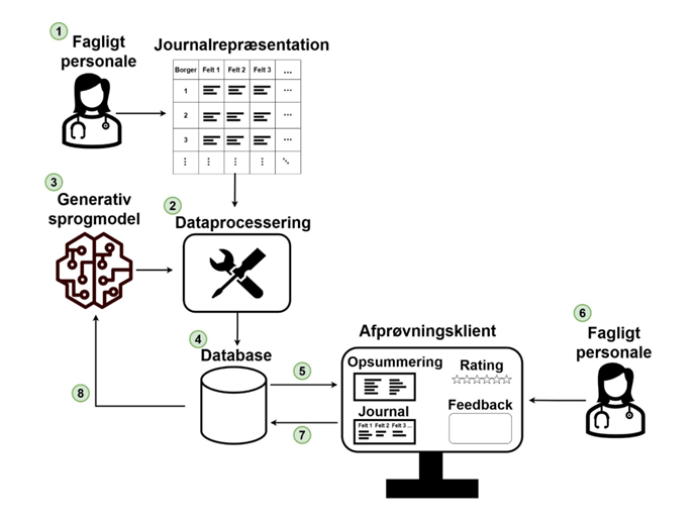
Afprøvnings- og udviklingsflow er illustreret på billedet ovenfor.
- Det faglige personale indskriver journalfelter for hver borger i et digitalt skema.
- Data processeres ved at udtrække data fra journalpræsentationen og strukturere det således, at data kan indhentes og indsættes korrekt i prompten af sprogmodellen.
- Den generative sprogmodel genererer en journalopsummering baseret på journaldataen. Prompten tunes initialt med henblik på at generere opsummeringer, der ligner de manuelt genererede opsummeringer.
- Opsummering og tilhørende journaldata indskrives i databasen
- Opsummering og tilhørende journaldata indlæses af afprøvningsklienten.
- Fagligt personale tilgår afprøvningsklienten og giver opsummeringerne en rating og feedback-kommentar.
- Rating og feedback journaliseres i databasen.
UC3: Indtaling af besøgsbeskrivelser
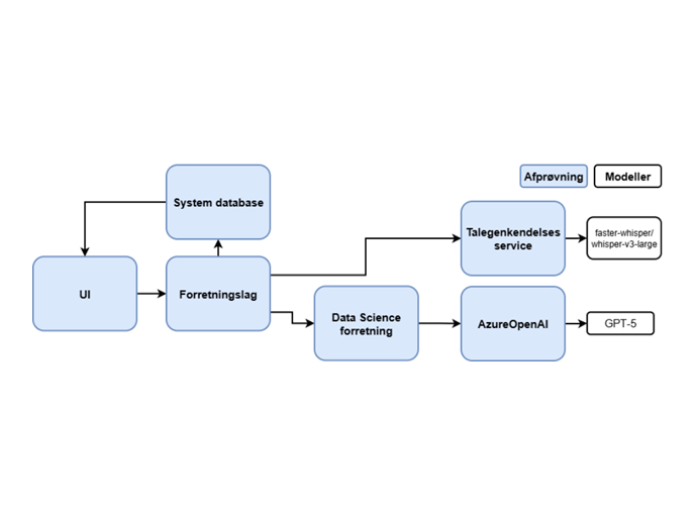
Løsningen deler en del komponenter med løsningen til UC1. For denne use case benyttes en ekstern hostet sprogmodel i form af GPT-5 via Azure AI til den generative komponent.